昆仑芯科技基础工具链开发负责人张钊 构建强大易用的软件栈,以网络技术开发赋能AI芯片生态发展
随着人工智能产业的迅猛发展,国产AI芯片的崛起已成为支撑国家算力基础设施的关键。在这一浪潮中,昆仑芯科技作为国内领先的AI芯片公司,其软件生态的构建,尤其是基础工具链的成熟度,直接关系到芯片能否在实际场景中释放强大算力。我们有幸采访了昆仑芯科技基础工具链开发负责人张钊,深入探讨了昆仑芯如何通过打造强大、易用的软件栈,并紧密结合网络技术开发,来驱动其芯片生态的繁荣发展。
一、软件栈:连接芯片硬件与应用场景的“桥梁”
张钊指出,在AI芯片领域,硬件是“身躯”,而软件栈则是“灵魂”与“神经网络”。一款芯片的峰值算力再高,如果缺乏高效、稳定、易用的软件支持,也难以被开发者广泛采纳,无法在复杂的实际业务中落地。昆仑芯的软件栈,正是致力于解决这一核心痛点。
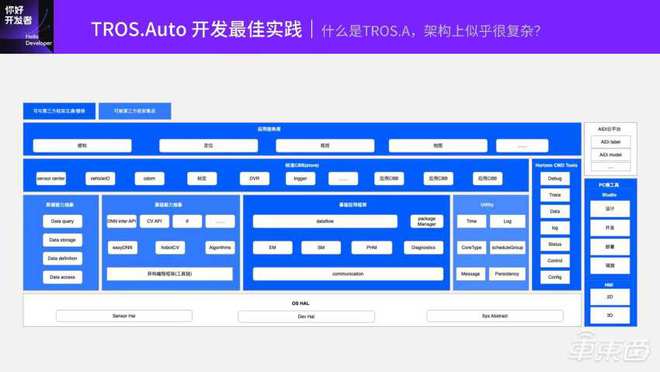
“我们的目标是为开发者提供从模型训练、压缩、转换到部署、推理、性能调优的全栈式软件解决方案,”张钊介绍道。这套软件栈的核心是深度优化的编译器、高性能算子库、驱动以及丰富的模型工具链。它不仅要充分“榨取”昆仑芯硬件的每一分算力,更要大幅降低开发者的使用门槛。例如,通过兼容主流的深度学习框架(如PyTorch, TensorFlow),并提供直观的模型迁移工具,开发者可以几乎无感地将现有模型部署到昆仑芯平台上,显著缩短了开发周期。
二、“强大”与“易用”的平衡之道
在张钊看来,“强大”与“易用”并非矛盾体,而是软件栈设计必须兼顾的两翼。
- 强大的性能表现:这背后是编译器团队的深度优化。张钊的团队针对昆仑芯芯片的架构特性,在计算图优化、算子融合、内存调度等方面进行了大量创新性工作。编译器能够智能地将用户模型转化为在芯片上执行效率最高的指令序列,确保计算资源的极致利用。针对视觉、语音、自然语言处理等不同领域的常见模型,团队提供了高度优化的预置算子库,这些算子经过手工精调,能实现接近理论峰值的性能。
- 极致的易用性体验:“再强大的工具,如果使用复杂,也难以普及。”张钊强调。为此,昆仑芯软件栈提供了清晰的API文档、丰富的示例代码、以及图形化的性能 profiling 工具。更重要的是,团队建立了活跃的开发者社区和技术支持体系,及时响应用户反馈,不断迭代优化开发体验。张钊认为,降低从“尝试”到“精通”的整个过程中的摩擦成本,是构建生态凝聚力的关键。
三、网络技术开发:软件栈赋能生态的“加速器”
在AI计算从单卡向大规模集群发展的趋势下,网络技术的地位日益凸显。张钊特别强调了网络技术开发在昆仑芯软件栈中的重要作用。
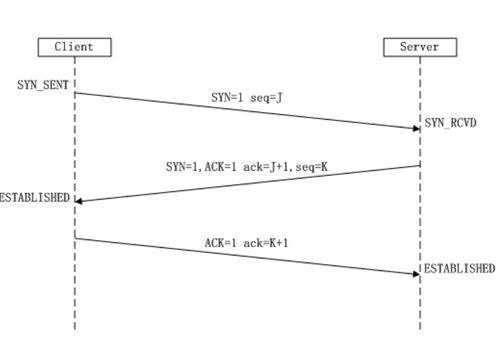
“无论是大规模分布式训练,还是云端推理集群,网络通信的效率都是制约整体系统扩展性和性能的瓶颈,”张钊解释道。昆仑芯的软件栈深度集成了高性能通信库,针对其芯片间的互联技术(如高速互联总线)进行了定制优化,实现了极低的延迟和高带宽。
在软件层面,团队开发了智能的通信调度和梯度同步算法,能够在大规模参数同步时有效减少等待时间,提升多卡、多机分布式训练的线性加速比。软件栈对RDMA(远程直接内存访问)等先进网络技术的支持,使得跨服务器的昆仑芯芯片能够像访问本地内存一样高效地协同工作,为构建超大规模AI计算集群提供了坚实的软件基础。
四、共创共赢,携手开发者繁荣生态
张钊最后表示,昆仑芯科技深知,生态的建设绝非一家公司可以独立完成。昆仑芯软件栈的持续进化,离不开与广大开发者、合作伙伴的紧密互动。公司通过开源部分工具、举办开发者大赛、与高校及研究机构合作等多种方式,积极融入更广阔的技术社区。
“我们提供的是‘工具箱’和‘高速公路’(强大的基础软件与网络能力),而真正的创新应用和行业解决方案,需要千行百业的开发者来共同创造,”张钊道,“我们将继续聚焦于软件栈的深度优化和体验提升,特别是在编译技术、大规模分布式系统支持以及新兴AI范式(如大模型)的适配方面持续投入,让昆仑芯的算力能够更便捷、更高效地服务于每一家企业和每一位开发者,共同推动中国AI计算生态的繁荣与发展。”
通过张钊的阐述,我们清晰地看到,昆仑芯科技正以扎实的软件工程能力和前瞻性的网络技术布局,为其AI芯片构筑起一道坚实的竞争壁垒。这条以“强大易用的软件栈”和“先进的网络技术开发”双轮驱动的生态建设之路,正助力昆仑芯在国产AI芯片的征程上行稳致远。
如若转载,请注明出处:http://www.shibuting.com/product/34.html
更新时间:2026-02-24 19:19:26